



EasyExcel基本使用
AI-摘要
Berry GPT
AI初始化中...
介绍自己
生成本文简介
推荐相关文章
前往主页
前往tianli博客
本文最后更新于 2024-08-10,文章内容已经超过7天没更新了。
EasyExcel是阿里巴巴开源的一个excel处理框架。使用简单,耗用内存少。EasyExcel能减少内存占用的原因是在解析Excel的时候没有将数据一次性全部加载到内存中,而是从磁盘一行一行读取数据。
1、注解
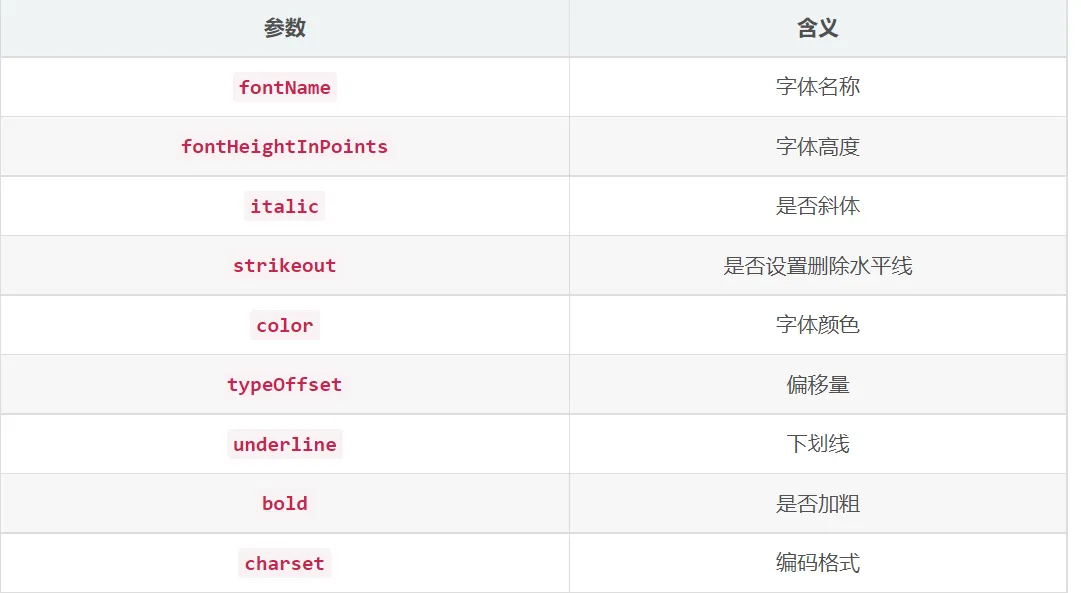
.png)
.png)
.png)
.png)
.png)
.png)
.png)
2、POI颜色枚举
颜色对照表:
.png)
package org.apache.poi.ss.usermodel;
public enum IndexedColors {
BLACK1(0),
WHITE1(1),
RED1(2),
BRIGHT_GREEN1(3),
BLUE1(4),
YELLOW1(5),
PINK1(6),
TURQUOISE1(7),
BLACK(8),
WHITE(9),
RED(10),
BRIGHT_GREEN(11),
BLUE(12),
YELLOW(13),
PINK(14),
TURQUOISE(15),
DARK_RED(16),
GREEN(17),
DARK_BLUE(18),
DARK_YELLOW(19),
VIOLET(20),
TEAL(21),
GREY_25_PERCENT(22),
GREY_50_PERCENT(23),
CORNFLOWER_BLUE(24),
MAROON(25),
LEMON_CHIFFON(26),
LIGHT_TURQUOISE1(27),
ORCHID(28),
CORAL(29),
ROYAL_BLUE(30),
LIGHT_CORNFLOWER_BLUE(31),
SKY_BLUE(40),
LIGHT_TURQUOISE(41),
LIGHT_GREEN(42),
LIGHT_YELLOW(43),
PALE_BLUE(44),
ROSE(45),
LAVENDER(46),
TAN(47),
LIGHT_BLUE(48),
AQUA(49),
LIME(50),
GOLD(51),
LIGHT_ORANGE(52),
ORANGE(53),
BLUE_GREY(54),
GREY_40_PERCENT(55),
DARK_TEAL(56),
SEA_GREEN(57),
DARK_GREEN(58),
OLIVE_GREEN(59),
BROWN(60),
PLUM(61),
INDIGO(62),
GREY_80_PERCENT(63),
AUTOMATIC(64);
}
2、读Excel
首先要对映射的实体类进行处理
@Data
@Builder
@AllArgsConstructor
@NoArgsConstructor
publice class Object{
@ExcelIgnore
private Integer id;
// 加上ExcelProperty注解,对excel中的列标题进行对应
@ExcelProperty(value = "编码", index = 0)
private String code;
@ExcelProperty(value = "名称", index = 1)
private String name;
}接下来对导入方法进行实现
public void importData(Object object, MultipartFile file) {
InputStream importFile = null;
try {
importFile = file.getInputStream();
} catch (IOException e) {
e.printStackTrace();
}
// 读数据,需要传入导入的文件、映射的实体类和监听器。由于监听器不是spring管理范围内,所以需要写成类的形式。监听器可以传入需要用到的数据或方法。
EasyExcel.read(importFile, Object.class, new ReadListener(objectService,object)).sheet().doRead();
}监听器Listener
监听器用于监听Excel导入的数据,可以对导入的数据逐行进行处理,也可以在所有数据解析完毕进行处理。
有个很重要的点 Listener 不能被spring管理,要每次读取excel都要new,然后里面用到spring可以构造方法传进去
@Slf4j
public class DemoDataListener implements ReadListener<Object> {
/**
* 每隔5条存储数据库,实际使用中可以100条,然后清理list ,方便内存回收
*/
private static final int BATCH_COUNT = 100;
/**
* 缓存的数据
*/
List<Object> dataList = new ArrayList<>();
/**
* 有业务逻辑这个可以是一个service,也可以传入Repository。当然如果不用存储这个对象没用。
*/
private Service service;
private Object object;
// 构造方法,需要传参数的话建议使用有参构造方法
public DemoDataListener(Service service, Object object) {
this.service = service;
this.object = object;
}
/**
* 这个每一条数据解析都会来调用
*
* @param data one row value. Is is same as {@link AnalysisContext#readRowHolder()}
* @param context
*/
@Override
public void invoke(Object object, AnalysisContext context) {
// 这里可以对每条数据进行校验处理
dataList.add(object);
//当缓存的数据量达到一定数量进行一次存储
if(dataList.size() >= BATCH_COUNT){
service.save(dataList);
//对缓存数据进行清空
dataList.clear();
}
}
/**
* 所有数据解析完成了 都会来调用
*
* @param context
*/
@Override
public void doAfterAllAnalysed(AnalysisContext context) {
// 如果校验时需要对导入的数据进行重复性校验,尽量要在所有数据解析完进行校验处理
/*如果不需要批量校验需要对缓存中剩下数据进行保存处理。例如每100条数据进行一次保存,160条数据
*最后只剩下60条不够,那么我们需要对剩下的数据进行处理。
*/
if(dataList.size() != 0){
service.save(dataList)
}
}
}
阅读建议
评论
匿名评论
隐私政策
你无需删除空行,直接评论以获取最佳展示效果